TravaZap e TravaLoL: como funcionam? - Parte 1
Esse é o primeiro de uma categoria de posts que eu vou fazer chamada de “direcionados para todos os públicos.”
Por causa disso, as coisas serão explicadas com mais detalhes, já que nem todos entendem os termos técnicos. Se você achar que eu estou falando muito, é por isso.
Além disso, as explicações que eu vou dar não são para alguém com doutorado em ciências da computação entender, mas sim para sua tia que tomou o travazap do rei do PIX saber o porquê do celular dela ficar lento. Então não seja chato de falar que eu esqueci de falar alguma coisa. Eu simplifiquei alguns termos para que a mensagem fique mais clara.
Dito isso, vamos lá:
Ultimamente os jogadores de League of Legends têm reclamado de um tal de travalol, ou trava lobby, uma espécie de programa que faz com que os jogadores sejam kickados das partidas.
No vídeo abaixo você pode ver um vídeo do canal “Que Crime” falando um pouco do Travalol:
Uma explicação básica⌗
O TravaZap funciona porque a mensagem do trava contém caracteres especiais.
O TravaLoL funciona por causa de um bug no client.
Essa explicação é a explicação que você vai achar na grande maioria dos sites. Ela está tecnicamente correta, mas falta algo a mais.
TravaZap⌗
O TravaZap é o que me deixou mais curioso, afinal como uma ingênua mensagem pode fazer um aplicativo inteiro travar?
No começo eu achei que era culpa da aplicação. Mas, para entender o motivo, eu preciso explicar primeiro o que é Unicode
Unicode⌗
Antes, um pouco de história.
Quando estamos aprendendo a ler, nós somos introduzidos primeiro ao alfabeto:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Depois, nós somos introduzidos aos numerais:
0 1 2 3 4 5 6 7 8 9
Nós sabemos que números e letras são coisas diferentes: números são mais usados pra contar e letras são mais usadas para escrever.
Infelizmente, o computador só enxerga números. Lembrem-se que o computador é, em seu núcleo, uma máquina para contar, então ele enxergar apenas números faz até que um pouco de sentido.
Esses números que o computador enxerga são chamados de bits, e eles são compostos por 0 e 1.
Oito bits são iguais a um byte. Um byte pode ir de 0 a 255.
Quando o computador começou a se popularizar, foi necessário mostrar texto ao usuário, mensagens mais claras do que meras luzes em um painel. Então começaram a inventar jeitos de representarem letras usando números.
O padrão mais usado durante muito tempo foi o ASCII. Ele usa um byte por letra (ou seja, vai de 0 até 255[*]), diferencia maiúsculas de minúsculas, e tem a maioria dos caracteres com acento. No ASCII, a letra A é codificada usando o número 65.
Infelizmente, o ASCII, devido a limitações de armazenamento na época, apenas guarda caracteres do alfabeto latino e alguns acentos. Se você quiser escrever, por exemplo, 私のコックは巨大です, você não vai conseguir usando ASCII. Obviamente era possível naquela época, já que os japoneses usavam computadores, mas não usando ASCII. Sim, você teria que trocar de encoding, o que provavelmente iria corromper seu texto, já que apenas os números e caracteres de letra maiúscula eram iguais entre os encodings da época.
Você já deve ter visto muitos textos assim, principalmente se você for mais velho:
Esse erro ocorre porque o sistema operacional, o Windows no caso, estava usando o encoding errado. O padrão é ASCII, mas o Windows 98 usava uma encoding chamada ISO-8859-1, também chamada Latin-1, para encodificar os caracteres em português.
As pessoas já estavam cansadas de problemas como esse, que limitam a comunicação. E olha que a diferença entre o Latin-1 pro ASCII era pequena: em muitos encodings, o que restava de semelhante ao ASCII eram apenas números e letras maiúsculas.
O desejo por um padrão universal começou, e o Unicode surgiu a partir daí.
[*] Tecnicamente o ASCII vai até 127, por motivos que fogem ao assunto desse post.
UTF-8⌗
O Unicode representa caracteres em valores chamados de codepoints, e eles são representados exclusivamente em hexadecimal.
Esses caracteres vão desde letras e números em diferentes idiomas até kanjis, hieroglifos e emojis.
Por exemplo, 💩 é representado pelo codepoint 1F4A9, equivalente a 128169 em decimal.
Todos os codepoints começam com U seguidos do número, então o codepoint que representa a atual situação do nosso amado país seria escrito U+1F4A9.
Porém, esses codepoints não dizem nada sobre como você os representa na máquina. Para isso, existem métodos de mapeamento. Os mais comuns se chamam UTF, ou Unicode Transformation Format, algo como Formato de Transformação Unicode, que vai mapear o codepoint em bytes, para serem usados pelo software.
O mais popular é o UTF-8. Nele, você usa no mínimo um byte e no máximo oito, se eu não me engano. Os bytes que cada codepoint depende do número do codepoint. Felizmente, os 127 primeiros caracteres têm o mesmo valor tanto em UTF-8, quanto Unicode e quanto ASCII, então não há mudanças (por isso que é tão popular). Todos os sistemas operacionais são compatíveis e usam UTF-8.
Existe o UTF-16, onde você usa entre dois e oito.
E existe o UTF-32, que você usa entre quatro e oito, se eu não me engano.
Muito embora, na prática, o limite máximo seja quatro.
Antigamente, o Windows usava um formato chamado UCS-2, que usava exatamente dois bytes por codepoint.
E, sim, letra e codepoint são coisas diferentes. Por exemplo, existem duas formas de escrever a letra á:
- U+00E1
- U+0061 U+0301.
Na primeira forma você usa o codepoint responsavel pela letra á.
Na segunda você usa 2 codepoints: um pra letra a (sem acento) e outro que representa o ato de acentuar o
codepoint anterior.
Navegando pelo texto⌗
Você deve estar se perguntando: o que isso tem a ver com o travazap?
Acalme-se.
É importante que você veja a explicação, principalmente na parte que eu falei que, no UTF-8, você usa no mínimo um byte e no máximo seis.
Não, o valor de bytes por caractere não é fixo.
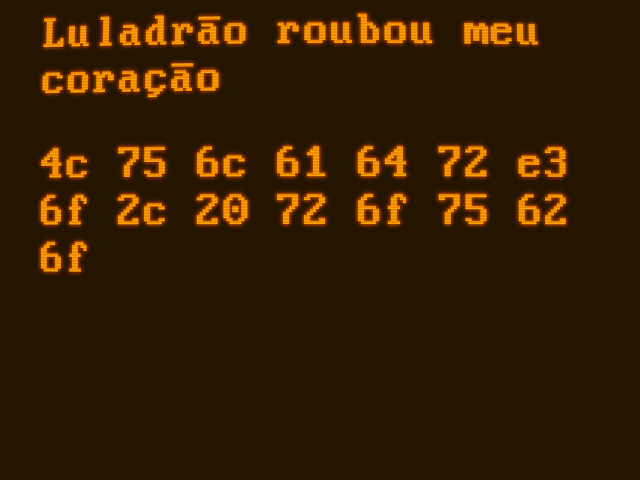
Por exemplo, se convertermos a frase “Luladrão roubou meu coração” para UTF-8, teremos: (cada número sendo um byte, em hexadecimal)
00000000 4c 75 6c 61 64 72 c3 a3 6f 2c 20 72 6f 75 62 6f |Luladr..o, roubo|
L u l a d r --ã-- o , r o u b o
00000010 75 20 6d 65 75 20 63 6f 72 61 c3 a7 c3 a3 6f |u meu cora....o|
u m e u c o r a --ç-- --ã-- o
Perceba que os caracteres com acento ocuparam dois bytes?
ãé representado pelos bytes C3 e A3 (195 e 163 em decimal).çé representado pelos bytes C3 e A7 (195 e 167 em decimal).
Antigamente, em ASCII, um caractere era igual a um byte. Então, para você, por exemplo, andar dez caracteres para frente num texto, você simplesmente pulava dez bytes. Você nem precisaria se preocupar no que está escrito, já que o tamanho é fixo.
Já no UTF-8, você precisa prestar atenção no byte que você está lendo, para ver se o caractere tem um ou mais bytes.
Isso torna operações de manipulação de texto, como contar letras e palavras, além de descobrir o tamanho de um pedaço de texto em caracteres, relativamente mais difícil.
Escrita⌗
Algo que se torna mais complicado é desenhar as letras que você vê na tela.
Antigamente, quando se usava apenas ASCII, o computador ordenava os 256 caracteres do ASCII em uma
lista na memória, e usava o valor da letra para se decidir qual caractere desenhar. Por exemplo, se
você pedisse para ele desenhar o caractere de valor 65, o computador iria ver o 65º caractere da lista,
que seria a letra “A”, e o desenharia onde você pediu.
Como eram apenas 256 valores, não tinha problema em ter uma tabela gigantesca em memória.
Porém, a primeira versão do Unicode já vinha com dezenas de milhares de “caracteres” (codepoints, na verdade). A primeira versão lançou ainda na década de 90, onde os computadores possuíam, em média, uns 128 MB de memória. Uma simples lista caberia, mas não sobraria muito para outros aplicativos.
Então os cientistas da computação inventaram jeitos melhores de guardar esses caracteres na memória, e diferentes formatos de fontes de computador nasceram. Jeitos melhores obviamente aumentaram a velocidade, mas aumentavam também o tamanho desses arquivos, além do consumo de memória da máquina.
Porém, uma coisa que mudou é que, antigamente, todos os caracteres tinham um tamanho fixo, de alguns pixels.
Por exemplo, se uma letra tem 7 pixels de largura, e você precisa escrever a palavra PAÇOCA, você sabe que
precisa reservar 7 pixels * 6 caracteres, ou seja, 42 pixels.
 “Paçoca” escrita em diferentes tipos de letra, para ilustrar os diferentes tamanhos
“Paçoca” escrita em diferentes tipos de letra, para ilustrar os diferentes tamanhos
Agora, um caractere pode ter diferentes tamanhos, então o programa nunca sabe qual vai ser o tamanho da letra que ele vai desenhar até ele desenhar. Sim, a altura ainda é conhecida, mas a largura não.
Problemas⌗
Então, nós temos dois problemas:
- Um caractere pode ser composto por vários codepoints.
- Um codepoint pode ser composto por vários bytes.
- Um caractere pode ter diferentes larguras.
- Além disso, um caractere pode ser desenhado de trás pra frente, ou de cima para baixo.
Identificar caracteres é difícil, mas desenhá-los na tela é ainda mais.
O motivo pelo qual isso não parece lento é que os programas geralmente, na hora de editar texto, ou deixam quatro bytes por codepoint, fazendo com que seja muito mais fácil de navegar, ou usam algoritmos que permitem navegação rápida, a custo de mais memória consumida.
Além disso, eles só desenham os caracteres que vão aparecer na tela, o que limita um pouco as coisas.
Voltando à questão.⌗
 Fonte: radaroeste.com.br
Fonte: radaroeste.com.br
Até agora, sabemos que:
- os caracteres podem ocupar mais de um byte.
- cada caractere pode ter diferentes tamanhos.
- a parte mais demorada envolve desenhar o caractere.
Dito isso, já posso explicar como funciona o travazap.
Não, não é nada a ver com os servidores do whatsapp. O Whatsapp usa uma linguagem chamada Erlang
para criar o programa que fica no servidor, enviando as mensagens para os aplicativos lhe mostrarem.
Essa linguagem tem um bom suporte a Unicode.
O aplicativo em si é feito em Java, se eu não me engano. Java tem um bom suporte a unicode.
E, para falar a verdade, o tratamento de Unicode já é conhecido faz tempo. Qualquer linguagem de programação tem funções que lidam com isso.
O problema está na hora de desenhar.
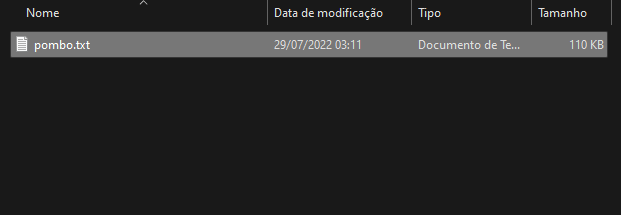
Isso é um travazap que eu peguei da internet, inalterado.
Ele tem 110 kB.
Pode não parecer muito, mas isso são, aproximadamente, 100 mil caracteres.
Você já pode perceber que tem algo errado, já que os travazaps não parecem ser tão grandes. No máximo eles têm uma tela ou duas. Isso não dá cem mil caracteres nunca, nem na menor fonte possível que você pode configurar no celular.
O problema, na verdade, está em desenhar.
A maior parte do travazap é composta por esses codepoints aqui:
U+2009U+200A
Se você souber inglês, vai ver que o nome do primeiro codepoint é algo como “ESPAÇO PEQUENO”, e o nome do segundo é algo como “ESPAÇO DO TAMANHO DE UM FIO DE CABELO”.
O 2009 é o segundo menor espaço disponível, medindo algo como 3 pixels. O 200A é ainda menor do que
isso. Lembrando que as telas de celular de hoje em dia possuem algo como 720 pixels de largura[2],
então cabem uns 300 caracteres desses por linha.
Esses dois caracteres não são muito difíceis de serem desenhados, mas, ainda assim, o WhatsApp precisa desenhá-los um a um. E, como os caracteres são bem pequenos, você precisa desenhar muitos deles para chegar até o final da tela.
Ao contrário do seu navegador, Chrome ou Firefox, que já é otimizado para lidar com muito texto ( lembrando que, tecnicamente, são 100 mil caracteres de uma vez ), o WhatsApp não é, e ele acaba travando.
Muitos travazaps contém codepoints que mudam a direção do texto, o que também afeta a velocidade de desenho, já que você precisa calcular a medida da letra de trás para frente, e ir andando pelo texto até achar o codepoint que volta a direção do texto ao normal.
Fato curioso: o travazap não funciona com SMS da mesma forma que com o WhatsApp.
Sim, o SMS suporta Unicode, mas ele tem um limite em bytes, e esse limite é relativamente
pequeno. Então você não vai ver tantos caracteres. MASSSS, você vai receber muitas mensagens
de uma vez, umas mil, uma atrás da outra.
É isso é o qe pode travar o seu celular
[2] 720 pixels virtuais. Na verdade, a tela tem, no mínimo, o dobro dessa resolução, mas ela é mais usada pelo sistema pra suavizar as bordas das letras e melhorar a definição das imagens.\ Para o aplicativo, é uma tela de 720 pixels.
Pronto, TravaZap explicado!
Na parte 2, que eu ainda vou escrever, eu vou falar mais ou menos como funciona o TravaLoL novo. Como eu ainda estou pesquisando, vai demorar um pouco mais.